MLLM-guided data synthesis
1 Introduction
One of the biggest challenges in the human motion generation domain is the shortage of data. The largest text-to-motion dataset in the research field, HML3D, contains only 14,616 motion clips and 44,970 descriptions using 5,371 distinct words. Even with data augmentation techniques, such as mirroring motions, the increase in diversity is minimal. This small dataset often leads to overfitting in general motion generation models. Leveraging our Animate 3D product, we can generate high-quality motion data. Thanks to advancements in large language models (LLMs) and multimodal LLMs (MLLMs), we are now able to create a massive and diverse synthetic dataset for text-to-motion generation tasks. Our privately owned dataset contains over 344,476 motion clips and descriptions, utilizing 12,139 distinct words.
2 Data Analysis for HumanML3D dataset
2.1 Similarity Test
As shown in Table 1, inspired by Text-Motion-Retrieval (TMR), we use MPNet to calculate the text description similarity between the training and test data. If a text in the training data has a similarity score of 90% or 95% or higher, we consider this an indication that a very similar semantic motion was used to train the model. As depicted in Table 1, such high text similarity between the training and test sets can potentially lead to overfitting, particularly in real-world scenarios.
 Table 1
Table 1
2.2 Action Distribution
We utilize the Part-of-Speech(POS) key from the HML3D ground truth data to visualize the action classes in the HML3D dataset. For improved clarity, we display only the top 30 classes in a bar chart and the top 50 in a pie chart. Figures 1 and 2 illustrate the action distribution in HumanML3D.
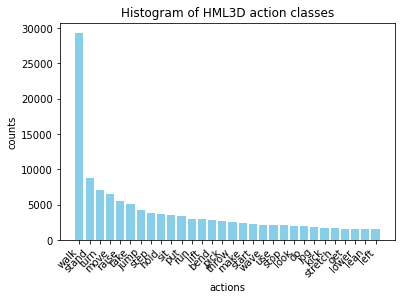 Figure 1
Figure 1
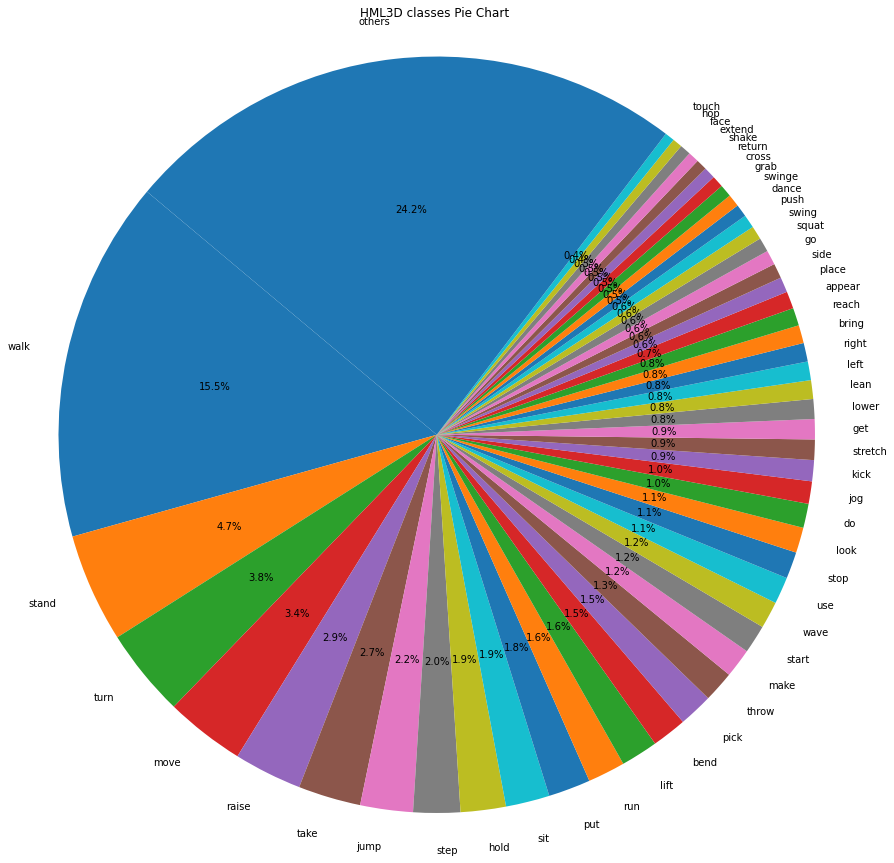 Figure 2
Figure 2
3 Data Preparation for DM dataset
3.1 Video-Motion data creation
*Our data is collected from A3D users who have voluntarily granted us permission to use their data to enhance the quality of our services.
Within our Animate 3D pipeline, we apply multiple self-evaluation methods, including a pose realism discriminator and a high-pass score for joint movement changes over time. We set thresholds to maintain action diversity while ensuring motion quality. Since our A3D pipeline also supports upper-body mode (with a focus on facial and finger tracking) and multi-person mode, we first filter out these specific samples from the dataset. After this process, we obtain a relatively high-quality video-motion dataset.
3.2 Video-Text data creation
We experimented with several MLLM/multimodal models, including Gemini 1.5, VideoChat2, MPlug2, and Valor. Additionally, we explored various hyperparameter tuning strategies and prompt engineering techniques to generate diverse outputs from each model. InternVideo was used to calculate the video-to-text retrieval Top-1 recall score for each model. We also conducted a quantitative evaluation based on user preferences. Figure 3 provides an example of our survey, and Table 2 presents the best video-to-text retrieval Top-1 recall scores for each model. Feedback from 17 users was collected through the survey is shown in Table 3.
 Table 2
Table 2
 Figure 3. User Preference Survey Example Question
Figure 3. User Preference Survey Example Question
 Table 3. User Preference Results
Table 3. User Preference Results
As shown, Gemini 1.5 emerged as the clear winner, which led us to choose it for generating our video-text data.
4 Data Analysis for DM dataset
4.1 Action Keyword Distribution
We applied the POS algorithm to the generated texts and analyzed their distribution. As shown in Figures 4 and 5, the most significant difference between the HumanML3D dataset and ours is that the top action class in our dataset is Dance, while HumanML3D is Walk.
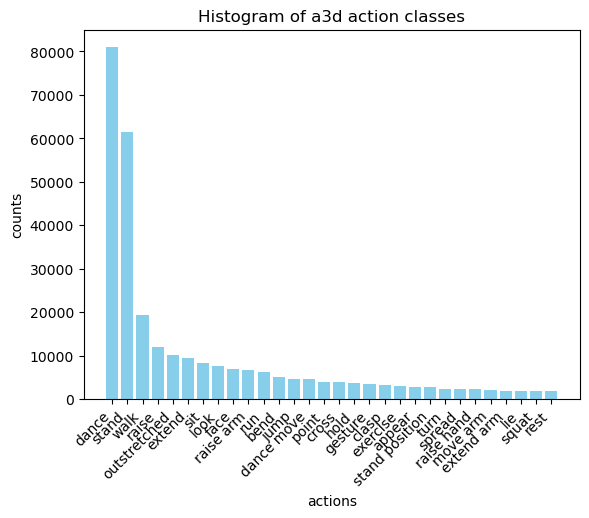 Figure 3
Figure 3
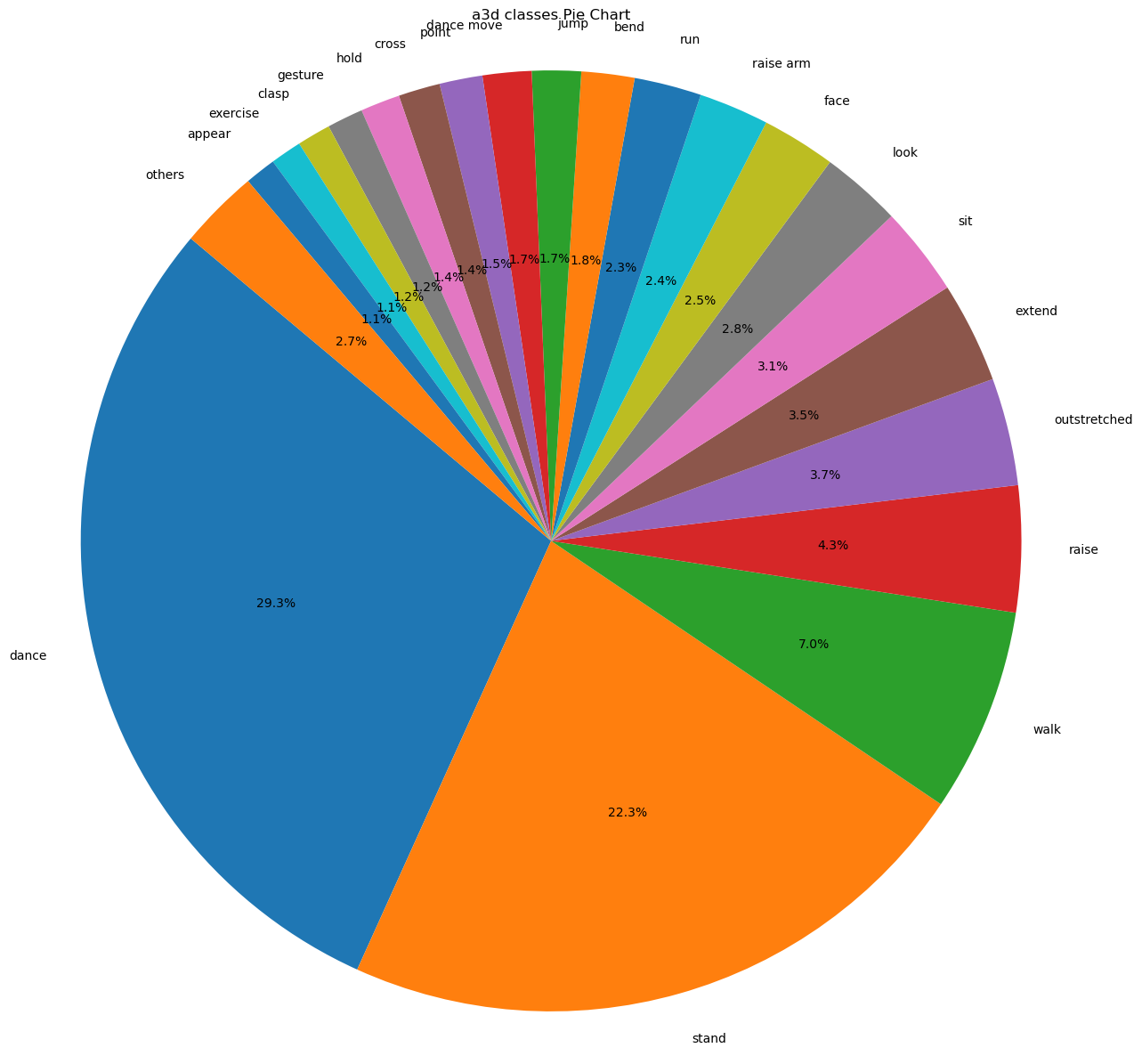 Figure 4
Figure 4
4.2 Action embedding Distribution
We aim to gain a deeper understanding of the relationship between embedding distributions and keyword distributions. First, we use TMR to convert motion and text into embedding space. After applying Principal component analysis(PCA), we visualize the relationship between text embeddings and visual embeddings to examine the modality alignment in a well-trained TMR model. We observed that there is a noticeable modality gap between text embeddings and motion embeddings.
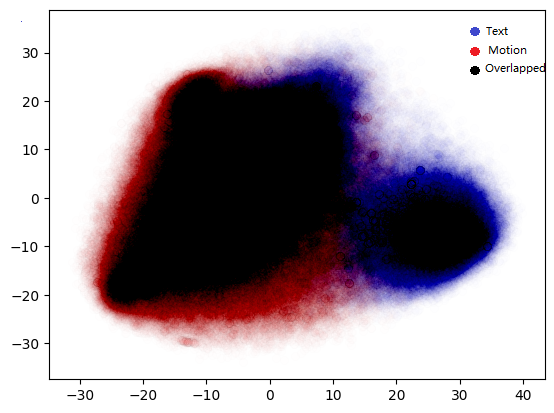 Figure 5
Figure 5
We also visualize the distribution of four keyword classes in both text and motion embedding spaces. Since the data points are transformed and reduced to 2D space, we believe that their distribution would be more distinguishable in the original dimensional space.
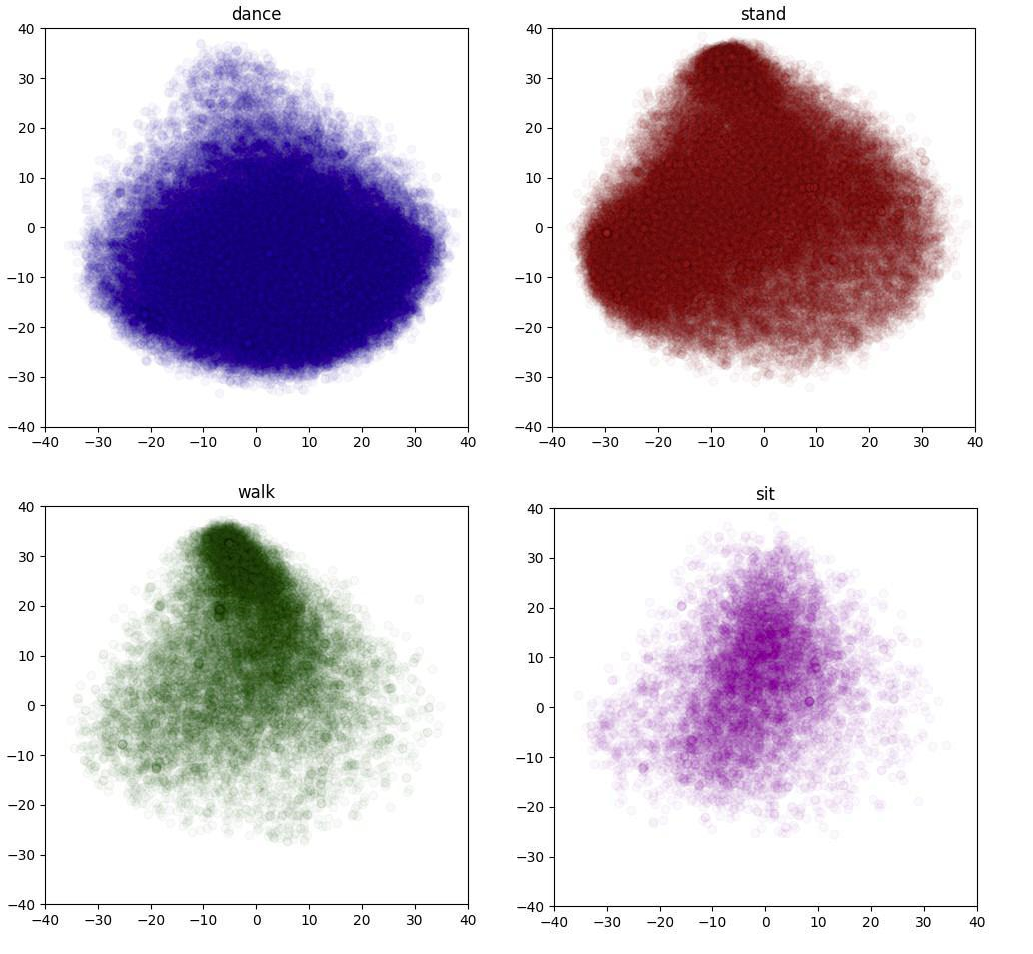 Figure 7.keyword classes distribution in Motion embedding space
Figure 7.keyword classes distribution in Motion embedding space
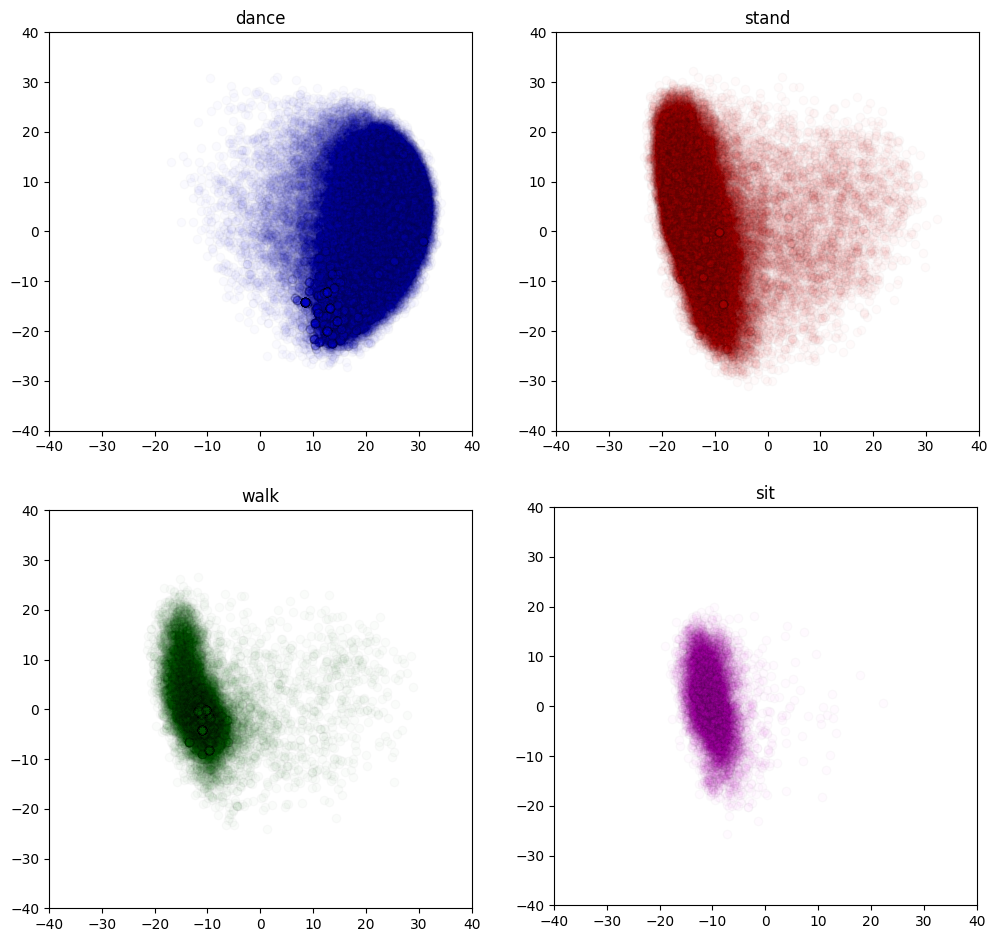 Figure 8.keyword classes distribution in Text embedding space
Figure 8.keyword classes distribution in Text embedding space
4.3 Text and Motion metric insight
We evaluated the performance of TMR for text-to-motion and motion-to-text retrieval on our dataset. The results fall within the expected range, which supports the effectiveness of our synthetic dataset.
 Table 3.Motion-Text Retrieval
Table 3.Motion-Text Retrieval
 Table 4.Text-Motion Retrieval
Table 4.Text-Motion Retrieval
5 Clustering
we identified that the data is not equally distributed. This imbalance could potentially harm the model’s performance if certain types of motions dominate the dataset. To address this bias, we decided to perform clustering to group similar types of actions together. This approach allows us to set different sampling rates for different clusters during training, mitigating the impact of dataset imbalance.
To achieve this, we first applied DBSCAN and K-means clustering algorithms. Based on the results, K-means yielded better performance, so we used K-means for the initial step of our clustering process.
Due to the characteristics of K-means, more centroids are clustered in denser areas to ensure that each cluster maintains a similar number of data points. This results in varying average distances from the centroid for each cluster. To achieve a more varied and representative final result, where each class is more distinct, we used hierarchical clustering to obtain an unbalanced clustering outcome. This approach helps group similar or repeated actions together more effectively.
To address the imbalance in the A3D dataset, we initially avoided hierarchical clustering due to its high computational expense and time consumption. With a total of 380,000 data points, hierarchical clustering requires computing an
𝑛
×
𝑛
distance matrix for each layer, which is impractical. Instead, we applied hierarchical clustering only to the centroids obtained from K-means, significantly reducing computation time. We fine-tuned the threshold to generate a final set of 12 clusters, ensuring that each cluster maintains semantic coherence while meeting the specified requirements.
We need to evaluate whether text embeddings or motion embeddings provide better clustering results. Figure 9 presents examples of clustering results for both motion and text embeddings. In these examples, motion clustering tends to focus on lower-level semantic motions, such as "raising hands in front of the chest and walking," which includes various actions with similar textual meanings like "zombie walk," "dumbbell lift walking," and "both hands shooting."
Conversely, text clustering results, as shown in Figure 10 with the example of "sword fight," reveal a broader range of movements that share the same textual meaning.
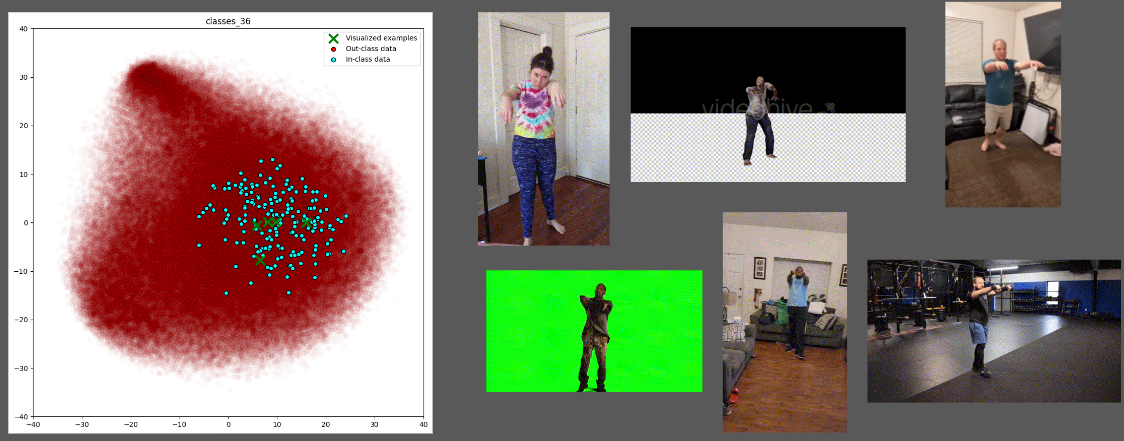 Figure 9. clustering based on motion embeddings
Figure 9. clustering based on motion embeddings
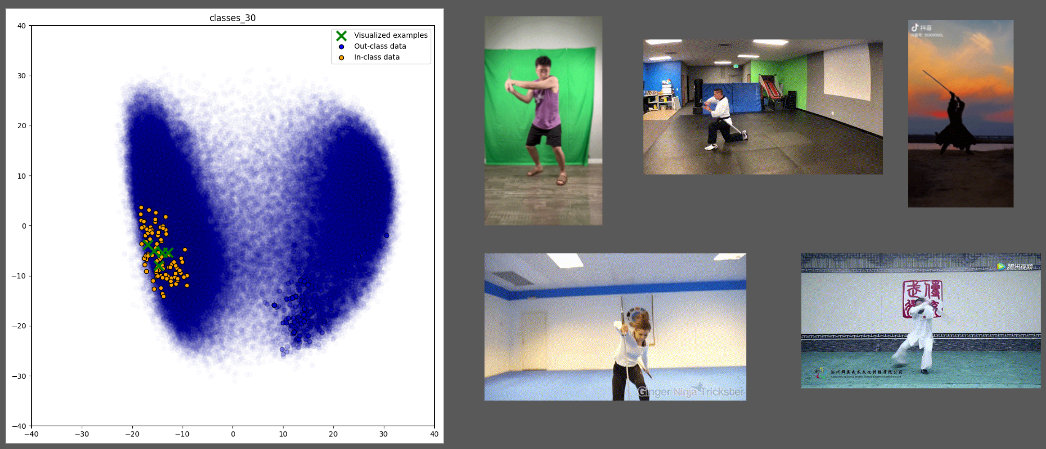 Figure 10. clustering based on text embeddings
Figure 10. clustering based on text embeddings
Ultimately, we chose text embeddings for clustering. Figure 11 displays the centroids of the 12 clusters across the entire sample space, while Figure 12 shows the data size for each cluster.
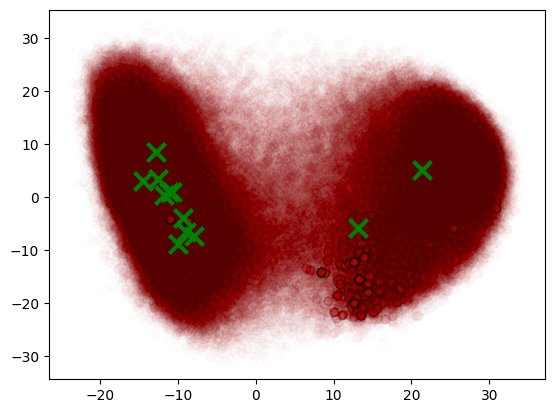 Figure 11
Figure 11
 Figure 12
Figure 12
6 Evaluation Metrics
 Table 5
Table 5
We tested our model on the HML3D test set for a clearer comparison. The results show that incorporating the DM dataset can futher improve the model's performance in HumanML3D dataset.
It is important to note that we replaced the text encoder and motion encoder in the original T2M paper with TMR for a more precise evaluation. As a result, the numbers reported are not directly comparable to those in state-of-the-art models' papers.
7 Visualization Results
8 Conclusion
Using MLLM-guided synthetic data, grouping data based on semantic meaning, and applying a weighted sampling ratio can significantly enhance motion generation accuracy.
9 Reference
Chen, S., He, X., Guo, L., Zhu, X., Wang, W., Tang, J., & Liu, J. (2023, April 17). Valor: Vision-audio-language omni-perception pretraining model and dataset. arXiv.org. https://arxiv.org/abs/2304.08345
Wang, Y., Li, K., Li, Y., He, Y., Huang, B., Zhao, Z., Zhang, H., Xu, J., Liu, Y., Wang, Z., Xing, S., Chen, G., Pan, J., Yu, J., Wang, Y., Wang, L., & Qiao, Y. (2022, December 7). InternVideo: General Video Foundation models via generative and Discriminative Learning. arXiv.org. https://arxiv.org/abs/2212.03191
Li, K., He, Y., Wang, Y., Li, Y., Wang, W., Luo, P., Wang, Y., Wang, L., & Qiao, Y. (2024, January 4). VideoChat: Chat-centric video understanding. arXiv.org. https://arxiv.org/abs/2305.06355
Xu, H., Ye, Q., Yan, M., Shi, Y., Ye, J., Xu, Y., Li, C., Bi, B., Qian, Q., Wang, W., Xu, G., Zhang, J., Huang, S., Huang, F., & Zhou, J. (2023, February 1). MPLUG-2: A modularized multi-modal foundation model across text, image and video. arXiv.org. https://arxiv.org/abs/2302.00402
Team, G., Georgiev, P., Lei, V. I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., Mariooryad, S., Ding, Y., Geng, X., Alcober, F., Frostig, R., Omernick, M., Walker, L., Paduraru, C., Sorokin, C., … Vinyals, O. (2024, August 8). Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv.org. https://arxiv.org/abs/2403.05530
Guo, C., Mu, Y., Javed, M. G., Wang, S., & Cheng, L. (2023, November 29). Momask: Generative masked modeling of 3D human motions. arXiv.org. https://arxiv.org/abs/2312.00063
Zhang, J., Zhang, Y., Cun, X., Huang, S., Zhang, Y., Zhao, H., Lu, H., & Shen, X. (2023, September 24). T2M-GPT: Generating human motion from textual descriptions with discrete representations. arXiv.org. https://arxiv.org/abs/2301.06052
Petrovich, M., Black, M. J., & Varol, G. (2023, August 25). TMR: Text-to-motion retrieval using contrastive 3D human motion synthesis. arXiv.org. https://arxiv.org/abs/2305.00976
Generating Diverse and Natural 3D Human Motions from Texts Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, Li Cheng CVPR, 2022